
The Clay guide to Conversational Data
How we use Clay to mine millions of pages of call transcripts to generate revenue


Most go-to-market teams are sitting on a goldmine they don’t even know exists.
Every call transcript you have from discovery sessions to customer conversations contain intelligence that should be improving how you build and sell your product.
Yet this context often remains buried in transcripts, lost in Slack threads, or trapped in individual reps’ heads.
At Clay, we’ve built our entire GTM engine around extracting and activating conversational data. That includes…
Auto-generating handoff docs and slides when deals move from sales → CX
Analyzing calls for competitive mentions and expansion ideas to start sales or upsell conversations
Mining conversations for internal feedback on our sales process or product
This approach has fundamentally changed how our GTM teams operate. Our CX team receives deep context before their first customer call and receives feedback that Clay feels like the company that “really understands” their business. Our sales team gets automated competitor intelligence—which our marketing team runs campaigns on. Our product team gets structured feedback from hundreds of deals. All without any manual work.
We’re turning every customer interaction into an actionable workflow to help us increase revenue and find GTM alpha. Read on to learn how to do it too.
Table of Contents
Guiding principle: conversations are structured data sources
Use your conversations as GTM alpha
Building seamless transitions between sales and CX (or between any team for that matter)
Finding conversational signals for selling or expanding customers
Mining conversations for feedback
How to construct the technical architecture to do it yourself
Process all your conversation in one place and build reusable intelligence
Extracting insights with JSON schemas in Clay
Speaker attribution: deeper details for precise targeting
Advanced implementation: interactive query capabilities
Implementation roadmap and success metrics
Conversations as competitive advantage
Guiding principle: conversations are structured data sources

Most people see conversations as unstructured “soft” data that requires manual interpretation. We see them as structured data sources waiting to be unlocked. Our philosophy centers on three principles:
Auto-extract key points: We automatically extract insights from every conversation using structured flows using formats that align with our team’s note-taking processes.
Process conversations in one central point: We run all conversations through a central pipeline that multiple teams can use.
Trigger automatic workflows based on notes: Our extracted insights immediately trigger workflows like pipeline generation campaigns, handoff automations, product feedback loops, and strategic reporting.
Based on our experience building conversational data workflows, we’ve identified three distinct categories where this approach creates immediate value—for CX, sales, and product feedback.
We’re going to go through each use case and then zoom out to help you figure out how to build the foundation for yourself.
1. Building seamless transitions between sales and CX
An impactful starting point for most teams is automating handoffs between GTM functions. At Clay, this happens when deals transition from sales to CX—but the principles apply to any cross-team transition.
The pre-automation problem: Customers would join their first post-sale call and face the dreaded “So, tell me about your business and why you bought Clay” conversation. Despite having 4-5 detailed discovery calls with sales, they’d need to restart from zero with their CX account manager. From the customer’s perspective, this felt like the company had amnesia. From the team’s perspective, it meant starting relationships from scratch despite weeks of prior context. Requiring people to make slides, docs, or handoff notes manually was too tedious to scale.
Our automated solution: Now, every time a deal closes, our system automatically processes all pre-sale conversations and extracts structured insights using a comprehensive JSON schema. Growth strategists receive auto-generated slide decks with complete customer context before their first call—no manual handoff work required.
Impact: Customers don’t repeat themselves across handoffs—when the growth strategist references specific challenges from the discovery call, customers immediately feel heard and understood. Growth strategists arrive armed with comprehensive context, eliminating catch-up conversation time per handoff. Sales reps avoid manual handoff documentation, and nothing falls through the cracks.
How to do it yourself:
Our system automatically processes all pre-sale conversations and extracts structured insights using a comprehensive JSON schema:
{
“icp_alignment”: “Strong fit - Series B SaaS company with 50+ person go-to-market team”,
“org_structure”: “Centralized RevOps team reporting to CRO,
distributed SDR teams by region”,
“primary_challenges”: [
“Data enrichment taking 40+ hours per week of manual work”,
“Lead routing delays causing 3-day response times”,
“Inconsistent data quality across 4 different tools”
],
“red_flags”: [
“Mentioned budget approval process requires board sign-off”,
“Previous implementation of similar tool failed due to adoption issues”
],
“expansion_potential”: “Interested in account-based marketing workflows for enterprise segment”,
“competitors_mentioned”: [
{
“name”: “ZoomInfo”,
“budget”: “$50K annually”,
“renewal_date”: “September 2024”,
“sentiment”: “Frustrated with data accuracy”
}
],
“key_stakeholders”: [
{
“name”: “Sarah Chen”,
“role”: “VP Revenue Operations”,
“influence”: “Primary decision maker”,
“concerns”: [”Implementation timeline”, “Team adoption”]
}
]
}
Practical implementation detail: Our system automatically generates slide decks for the growth strategist team using these extracted insights. Instead of manually creating customer overview presentations, the workflow pulls from the structured Call Insight records to create comprehensive context decks that include ICP alignment, organizational structure, key challenges, red flags, and stakeholder mapping.
The slide generation workflow operates on a standardized template that adapts based on the extracted data. For enterprise deals, the deck automatically includes sections on decision-making processes, technical requirements, and compliance considerations that emerged from sales conversations. For SMB customers, it emphasizes implementation timeline concerns, budget constraints, and adoption challenges. The system even identifies which growth strategist should handle the account based on industry expertise or previous experience with similar customer profiles mentioned in the conversations.
This eliminates manual prep work per handoff while ensuring nothing gets missed. More importantly, it creates consistency across our customer success team—every growth strategist receives the same quality of customer intelligence regardless of how detailed the handoff notes were from sales.
2. Finding conversational signals for selling or expanding customers

The second category focuses on extracting signals that directly generate new pipeline opportunities. We’ve built several core workflows that consistently drive measurable revenue results.
The pre-automation problem: Sales reps would hear competitors mentioned, budget numbers discussed, and renewal dates referenced during calls—but this intelligence rarely made it into CRM or triggered any systematic follow-up. Reps might remember to log “Uses ZoomInfo” but miss the renewal date, budget amount, or which specific person expressed frustration. Expansion opportunities mentioned in passing during customer calls disappeared into call notes that nobody systematically reviewed. Without structured capture, this revenue intelligence was lost.
Our automated solution: Now, every conversation gets analyzed for competitive mentions, budget discussions, renewal timelines, and expansion signals. When a prospect says “We spend $50K annually on ZoomInfo and it renews in September, but we’re frustrated with data accuracy,” our system automatically creates structured competitive intelligence records and triggers targeted displacement campaigns—without any manual work from the sales team.
Analyze calls for competitive mentions
We analyze every conversation for competitor mentions, budget discussions, and renewal timelines. When a prospect says “We spend $50K annually on ZoomInfo and it renews in September, but we’re frustrated with data accuracy,” our system creates structured records with granular detail like:
Competitor Intelligence Object: Competitor name, current spend, contract details, renewal timeline, decision-making stakeholders
Sentiment Analysis: Specific frustration points and satisfaction gaps
Opportunity Scoring: Displacement probability based on budget size, renewal timing, and pain point severity
Stakeholder Mapping: Who mentioned the frustration, their role, and influence level
Then, the system immediately creates a “ZoomInfo Displacement” campaign targeting the specific stakeholder who mentioned their frustrations. The campaign includes relevant case studies showing ZoomInfo-to-Clay migrations, ROI calculators based on their mentioned budget, and time-sequenced outreach aligned to their renewal timeline.
Analyze calls for customer expansion signals
Calls are a great way to detect customer expansion use cases. When customers mention interest in specific capabilities during calls, our system captures this and automatically triggers targeted campaigns.
For example, our colleague Spencer built a way to ID the vendors prospects currently use and what new use cases they want to explore. This information feeds directly into marketing email campaigns and product launch targeting. (Every time we launch a new product feature, we can immediately identify and target customers who previously expressed interest in that specific use case).
Here’s how this works in practice:
When we launched our Clay Sequencer product for automated outreach sequences, we queried our conversational database for all mentions of “automation,” “sequences,” “follow-up workflows,” and related terms from the past 12 months. The system identified 340 prospects and customers who had expressed interest in automation capabilities during sales or customer success calls. We automatically segmented these contacts based on company size, current tool stack, and specific automation challenges mentioned in their conversations.
The campaign launched with three different email tracks: enterprise prospects received messaging about replacing complex automation tools, mid-market prospects got content about scaling outreach efficiently, and existing customers saw expansion messaging about adding automation to their current workflows. Because we knew exactly what each person had said about automation needs, we could reference their specific challenges in outreach messages.
Use call data to better target marketing campaigns
When we launch new product features, we query our conversational database to identify all customers who previously mentioned interest in related use cases. This allows us to immediately target the most relevant audience with personalized messaging about capabilities they specifically requested.
We also use conversational intelligence to trigger ongoing nurture campaigns. When someone mentions they’re “evaluating marketing automation tools” or “looking at ABM solutions,” they automatically enter specialized nurture sequences with relevant case studies, comparison guides, and educational content specific to their expressed interests. The campaigns reference not just what they’re interested in, but who mentioned it and in what context, creating highly personalized messaging that feels like a natural continuation of their sales conversations.
The attribution advantage: The critical differentiator is speaker-level attribution. We don’t just capture that “they use ZoomInfo”—we capture that “Sarah from RevOps mentioned frustration with ZoomInfo’s data accuracy during the discovery call.” This granular attribution means our outreach targets the right person with the right message at the right time.
3. Mining conversations for feedback
Conversational data also helps us improve our product and sales motion.
The pre-automation problem: Traditional closed-lost analysis relied on sales reps manually categorizing why deals fell through—often incomplete, inaccurate, or overly simplified. A rep might mark “pricing” when the real issue was the way they mentioned GPDR compliance, or “chose competitor” without capturing which competitor or why. Product teams received anecdotal feedback filtered through multiple layers, losing the nuance of actual customer language. Sales leadership had limited visibility into systematic failure patterns or what differentiated successful reps from struggling ones.
Our automated solution: Now, our system processes actual conversation transcripts from lost deals to identify systematic patterns with unprecedented granularity. Instead of relying on rep recollection, we extract the real reasons—with specific quotes, stakeholder objections, and competitive factors—directly from the calls. This intelligence automatically feeds product roadmaps, sales training programs, and strategic planning discussions.
Automated closed-lost analysis
Our system processes actual conversation transcripts from lost deals to understand systematic failure patterns with unprecedented granularity.
Our closed-lost extraction schema includes:
{
“primary_loss_category”: “missing_integration”,
“detailed_reason”: “Required Marketo integration for European compliance workflows that we don’t currently support”,
“stakeholder_objections”: [
{
“stakeholder”: “GDPR Compliance Manager”,
“objection”: “Data residency requirements”,
“severity”: “deal_killer”
}
],
“competitive_factor”: “Chose Clearbit due to EU data centers”,
“deal_stage_lost”: “technical_evaluation”,
“recovery_possibility”: “low - fundamental capability gap”
}Sales training and enablement
The closed-lost analysis creates a detailed feedback loop for sales training that goes beyond simple win/loss categorization. Our sales leadership receives structured documentation showing not just what happened, but specific quotes and conversation patterns that led to deal outcomes.
For example, our analysis revealed that newer reps had lower win rates when prospects raised “implementation complexity” concerns during technical evaluation calls. When we analyzed the actual conversation transcripts, we found that experienced reps responded to implementation questions by simplifying technical concepts and providing concrete timelines, while newer reps often went deeper into technical details that increased prospect anxiety.
One experienced rep’s transcript showed this approach: “I understand implementation seems complex. Let me break down what the first 30 days actually look like for customers like you. Week one is just connecting your CRM, which takes about 15 minutes. Week two, we build three simple workflows together. By week three, you’re seeing results.” Meanwhile, a newer rep’s response went: “Implementation involves API configurations, webhook setups, data mapping protocols, and schema validation processes that integrate with your existing tech stack.”
This analysis led to specific coaching programs focused on “technical translation”—helping new reps explain complex capabilities in business-impact terms rather than technical specifications. We built role-playing scenarios based on actual conversation patterns that led to successful outcomes versus losses.
Beyond sales: support ticket integration
We don’t limit conversational data to sales conversations. Our system also processes support tickets and customer success sessions to identify product feedback patterns and user experience insights that feed directly into product development prioritization.
Bruno built workflows that analyze support conversations for recurring themes like feature requests, integration needs, and usability concerns. For instance, when analyzing three months of support tickets, we discovered that a significant portion of integration support requests involved Marketo connections, with customers frequently mentioning “European compliance workflows” and “GDPR automation” as their primary use cases.
This intelligence directly influenced our product team’s decision to prioritize European compliance features in the Marketo integration, rather than focusing on general automation capabilities that seemed more popular in sales conversations but weren’t driving actual support volume. The support conversation analysis revealed the gap between what prospects say they want and what customers actually struggle with post-implementation.
How to construct the technical architecture to do it yourself
You have to solve several engineering and operational challenges to make conversational data actionable.
Process all your conversation in one place and build reusable intelligence
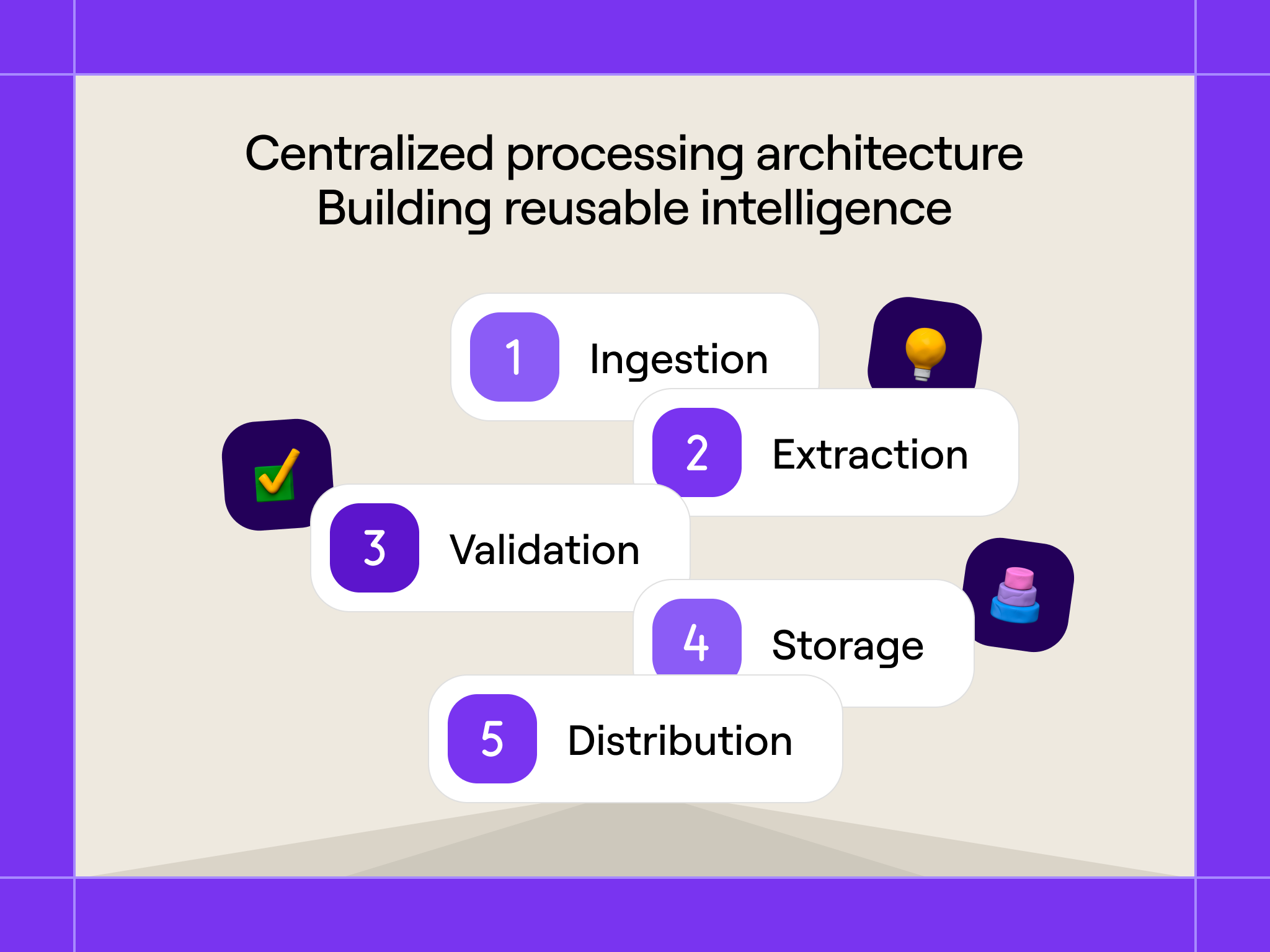
We architected a central pipeline that creates reusable “Call Insight” records in Salesforce. This architectural decision multiplies the value of each conversation by making insights available across multiple workflows.
The processing pipeline: Every conversation flows through our standardized extraction system:
Ingestion: Our conversational intelligence platform captures conversations and triggers our processing workflows within minutes of call completion
Extraction: Multiple specialized prompts extract different insight categories in parallel
Validation: Automated quality checks ensure schema compliance and logical consistency
Storage: Validated insights populate custom Salesforce objects with proper field mapping
Distribution: Downstream workflows consume pre-processed insights rather than raw transcripts
Call Insight data model: Our core Salesforce object structure includes:
Call Insight Header: Metadata, participants, timestamp, processing status
Competitive Intelligence: Competitor mentions, sentiment, budget, timeline details
Use Case Insights: Current state, expansion interests, tool stack details
Stakeholder Mapping: Individual participants, roles, influence, specific concerns
Opportunity Signals: Buying timeline, budget authority, decision process details
Practical architecture benefits: This centralized approach provides two critical advantages. First, individual workflows can focus on their specific value creation rather than handling conversation processing complexity. When our team builds a new campaign automation, they query existing Call Insight records rather than re-processing raw transcripts. Second, insights get leveraged across multiple use cases without duplicate processing costs or delays.
For example, competitor mentions extracted once get used by both the displacement campaign system and the competitive intelligence reporting for sales leadership. Use case insights feed both marketing campaign targeting and customer success expansion workflows. This architectural decision transforms each conversation from a single-use interaction into a multi-purpose intelligence asset.
Extract insights with JSON schemas in Clay
The foundation of usable conversational data is constraining AI outputs to structured, queryable formats. Rather than getting variable free-form responses, you need to define precise JSON schemas that specify exact fields, data types, and acceptable values for every extraction workflow.
Why this matters: Without structured schemas, AI returns inconsistent free-form text that’s impossible to query programmatically. One extraction might return “They’re frustrated with their current vendor” while another returns “High dissatisfaction levels noted.” Structured schemas ensure every extraction follows the same format, making the data immediately usable in downstream workflows.
Step 1: Identify what information you actually need
Don’t design schemas in a vacuum. Start by talking to the people who will use the extracted data.
For customer handoffs, sit down with your customer success team and ask: “What do you wish you knew before every first call with a new customer?” Write down their answers verbatim. You’ll likely hear things like “their main challenges,” “who the decision makers are,” “what they’re hoping to accomplish,” and “any concerns or red flags mentioned during sales.”
For competitive intelligence, interview your sales team: “What competitor details would change how you approach a deal?” You’ll probably hear “which competitor they’re using,” “how much they’re spending,” “when their contract renews,” and “what they’re unhappy about.”
Build your schema around these action-oriented needs. Every field in your schema should answer the question: “What will we do differently based on this information?”
Step 2: Start simple and iterate
Don’t try to capture everything in your first schema version. Start with 5-8 core fields that address your team’s top priorities.
Our handoff schema started with 15 fields because we thought we needed comprehensive data. After three months, we analyzed which fields our growth strategists actually referenced in customer calls. Half weren’t being used at all. We consolidated to 8 high-value fields:
ICP alignment (are they a good fit?)
Org structure (who reports to whom?)
Primary challenges (what problems are they solving?)
Red flags (what could derail this relationship?)
Expansion potential (what might they buy next?)
Competitor mentions (what tools are they replacing or comparing us to?)
Key stakeholders (who are the decision makers and what do they care about?)
Buying motivations (why did they choose us?)
Each field directly informs how growth strategists approach customer relationships. Nothing in the schema is “nice to have”—everything drives specific actions.
Plan to revisit your schema monthly for the first quarter. Track which fields get used in actual workflows and which get ignored. Remove unused fields and add new ones based on team feedback.
Step 3: Set up your data ingestion
Conversational intelligence platforms provide multiple ways to access the data in your call transcripts. You can use API and webhook capabilities to trigger processing workflows automatically.
Set up a webhook in your favorite platform that fires when calls are completed. This webhook should include the call metadata (participants, duration, timestamp) and provide access to the full transcript. CI platforms capture both calls and other revenue interactions, giving you a comprehensive view of customer conversations across channels.
Your processing system should receive this webhook payload and queue the conversation for extraction. We process conversations within minutes of call completion to ensure insights are available while the conversation is still fresh and relevant.
Step 4: Define your JSON structure
Once you know what fields you need, structure them in JSON format with clear data types and constraints.
Here’s a simplified example for competitive intelligence:
{
“competitor_name”: “string (required)”,
“current_spend”: “string or null (format: ‘$X annually’ or ‘$X/month’)”,
“contract_end_date”: “string or null (format: ‘YYYY-MM-DD’ or ‘Q1-Q4 YYYY’)”,
“renewal_timeline”: “string or null (options: ‘imminent’, ‘within_3_months’, ‘within_6_months’, ‘beyond_6_months’, ‘unknown’)”,
“primary_frustrations”: “array of strings”,
“satisfaction_level”: “string (options: ‘satisfied’, ‘neutral’, ‘frustrated’, ‘actively_looking_to_switch’)”,
“mentioned_by”: {
“name”: “string”,
“role”: “string”,
“influence_level”: “string (options: ‘decision_maker’, ‘influencer’, ‘end_user’)”
}
}Notice the specific constraints: dates have expected formats, satisfaction levels are limited to predefined options, and numeric fields specify their units. This prevents AI from returning “they’re unhappy” in one extraction and “dissatisfied” in another—both get mapped to “frustrated” based on your prompt instructions.
Step 5: Write detailed prompt instructions
Your extraction prompt needs three components:
The JSON schema (what structure you want)
Edge case handling (what to do when information is unclear or missing)
Output examples (showing properly formatted results)
Here’s how we structure our competitive mention prompt:
Extract competitive intelligence from this conversation transcript.
OUTPUT SCHEMA:
[Include your JSON schema here]
EDGE CASE INSTRUCTIONS:
- If multiple competitors are mentioned, create separate objects for each
- If no budget amount is mentioned, set current_spend to null—do not estimate
- If renewal timeline is vague (”sometime next year”), extract as the full year range “Q1-Q4 2024” rather than guessing specific quarters
- When speakers express frustration, capture their specific language in primary_frustrations—don’t interpret or paraphrase their words
- If the speaker’s role is unclear, set influence_level to “end_user” as the default
- Only mark satisfaction_level as “actively_looking_to_switch” if they explicitly mention evaluating alternatives
EXAMPLE OUTPUT:
[Include 2-3 examples of properly formatted JSON responses]
TRANSCRIPT:
[The actual conversation transcript gets inserted here]The edge case instructions are critical. They come from reviewing hundreds of extractions and identifying where AI makes inconsistent decisions. Every time you find inconsistent outputs during your quality reviews, add a specific instruction to handle that scenario.
Step 6: Use automated validation
Set up automated checks that run on every extracted record before it enters your CRM or workflow systems. Each check should flag records that fail validation for manual review.
Here are some essential validation checks we use:
Schema compliance: Does the JSON structure match your defined schema? Are all required fields present?
Data type validation: Are dates in the correct format? Are predefined options (like satisfaction_level) using only allowed values? Are numeric fields actually numbers?
Logical consistency: If a renewal_timeline is specified, is there also a competitor_name? If satisfaction_level is “actively_looking_to_switch,” are there primary_frustrations listed?
Completeness thresholds: Are text fields substantive (more than 10 characters)? Or did the AI return generic placeholders like “Various concerns mentioned”?
Required field population: For fields marked as required, is there actual content rather than null values or empty strings?
Build a simple dashboard that shows validation failure rates by type. This helps you spot systematic issues with your prompt or schema design.
Step 7: Create a manual review process
Despite good prompts and validation, some extractions will need human review. Build a weekly process where someone reviews failed validations and identifies patterns.
Here’s our process at Clay:
Monday morning: Review all validation failures from the previous week (usually 5-10% of total extractions)
Categorize failures: Group by failure type (date format issues, missing required fields, logical inconsistencies, etc.)
Identify patterns: If the same type of failure appears 5+ times, it’s a prompt problem, not a data problem
Update prompts: Add specific instructions to handle the failure pattern
Reprocess failed records: Run the failed extractions through the updated prompt
For example, we noticed that vague date references like “our contract is up soon” weren’t being handled consistently. Sometimes the AI extracted “within_3_months,” other times “imminent,” other times it left the field null. We added this specific instruction: “For phrases like ‘soon,’ ‘coming up,’ or ‘in the near future’ without specific months, use ‘within_3_months’ as the renewal_timeline.”
After three months of this review process, our validation failure rate dropped from 12% to under 3%, and the failures that remain are genuinely ambiguous cases where human judgment is appropriate.
Find who said what: deeper details of speaker attribution for precise targeting
Advanced conversational intelligence requires capturing not just what was discussed, but who said it. Conversational intelligence platforms provide speaker-attributed transcripts that enable precise stakeholder mapping and targeted follow-up.
Technical implementation: The system processes our call transcripts immediately after each sales conversation. We use Claude with a structured prompt that includes our JSON schema, conversation transcript, and specific extraction instructions. The output populates custom Salesforce objects that our growth strategist team accesses through dashboards and automated slide deck generation:
{
“competitive_mention”: {
“competitor”: “ZoomInfo”,
“budget”: “$50K annually”,
“renewal_date”: “September 2024”,
“speaker”: {
“name”: “Sarah Chen”,
“role”: “VP Revenue Operations”,
“email”: “sarah@prospect.com”,
“sentiment”: “frustrated”,
“specific_quote”: “ZoomInfo’s data accuracy has been really disappointing”
}
}
}Strategic targeting applications: This speaker-level attribution dramatically improves campaign targeting and account strategy:
Competitive displacement: Target the specific person who expressed frustration rather than generic account-based outreach
Use case expansion: Route expansion opportunities to stakeholders who expressed interest in specific capabilities
Objection handling: Identify which stakeholders raised which concerns for targeted follow-up
Champion development: Recognize advocates and equip them with relevant supporting materials
Implement interactive query capabilities
We allow GTMEs to query conversational data directly through natural language. Using our integration with Dust, team members can ask questions like “Tell me about what happened on this call with Acme Corp” or “What specific concerns did their compliance team raise?” and get structured responses based on the processed conversational data.
How it works in practice
This creates an interactive intelligence layer where team members can explore conversational context without manually reviewing transcripts.
For example, a growth strategist preparing for a customer expansion conversation can ask: “What use cases did they mention interest in during their last three calls?”
The system responds with structured context, e.g.: “During the Q3 business review, the Marketing Director mentioned wanting to explore ABM workflows for their enterprise segment. In the September check-in, their RevOps lead asked about Slack integration capabilities. Most recently, they expressed interest in expanding to their European team in a GDPR compliant way.”
What makes this valuable
The system can answer specific questions about stakeholder concerns, competitive mentions, technical requirements, or expansion opportunities by querying the structured data we’ve extracted from conversations. This transforms historical conversations from static transcripts into searchable, actionable intelligence that team members can explore conversationally.
Rather than re-reading months of call notes or searching through transcripts manually, team members get immediate, contextual answers to specific questions. The responses include relevant quotes and timestamps, enabling more strategic preparation for customer conversations.
Real-world applications
Our customer success team uses this capability extensively before renewal calls. Instead of spending 30 minutes reviewing call history, they ask targeted questions:
“What challenges have they mentioned with their current implementation?”
“Which team members seem most engaged with the product?”
“Have they mentioned any expansion interests or new use cases?”
“What concerns did their legal team raise during the sales process?”
The system provides context-rich answers with specific quotes and attribution, enabling CS reps to enter renewal conversations already knowing the key themes, risks, and opportunities. This preparation advantage helps customers feel like we truly understand their business because we reference specific concerns and interests they’ve mentioned over time.
Implementation roadmap and success metrics
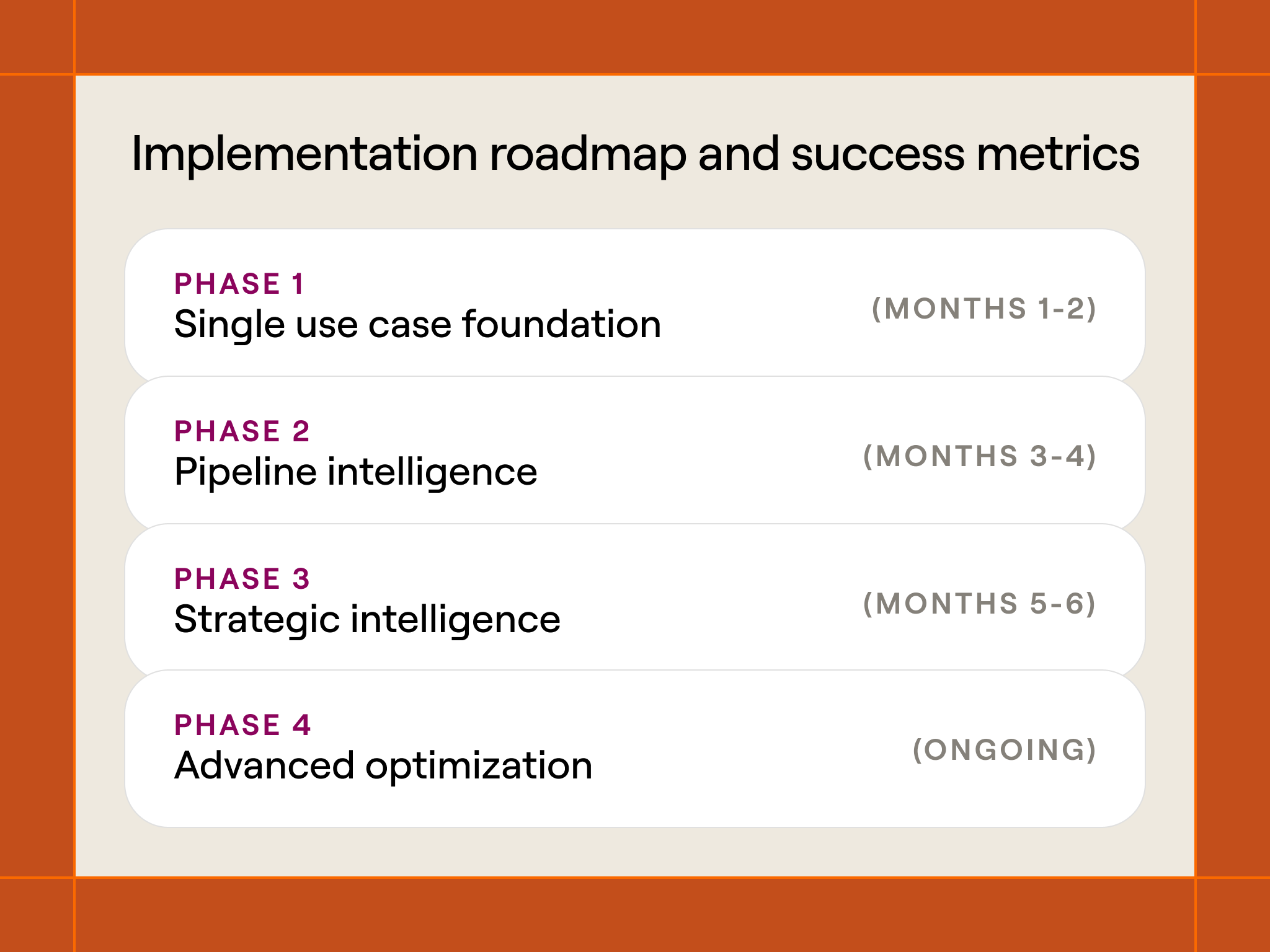
Based on our experience scaling conversational intelligence from proof-of-concept to mission-critical GTM infrastructure, here’s how we recommend other teams approach this systematically:
Phase 1: single use case foundation
Start with handoffs: The highest-impact starting point is automating one key handoff in your GTM process. Choose the transition with the greatest context loss and customer friction—typically sales to customer success or SDR to AE.
Technical foundation: Build basic extraction capabilities using a simple JSON schema focused on the specific handoff use case. Start with 5-7 key fields rather than attempting comprehensive extraction.
Success metrics: Measure handoff efficiency (time to first meaningful customer conversation), customer satisfaction scores, and manual documentation reduction.
Phase 2: pipeline intelligence
Add competitive intelligence: Expand extraction to capture competitor mentions, budget discussions, and renewal timelines. Build basic campaign automation triggered by competitive signals.
Schema evolution: Enhance JSON schemas based on Phase 1 learnings. Add speaker attribution and sentiment analysis for more precise targeting.
Success metrics: Track pipeline generated from conversational signals, competitive displacement win rates, and campaign response rates compared to cold outbound.
Phase 3: strategic intelligence
Closed-lost analysis: Implement systematic analysis of lost deals to identify product gaps, process failures, and market positioning opportunities.
Cross-functional integration: Share conversational insights with product, marketing, and strategic planning teams. Build reporting dashboards for leadership visibility.
Success metrics: Measure product feedback cycle time, content performance improvements, and strategic decision-making speed based on conversational intelligence.
Advanced optimization (ongoing)
Predictive enhancement: Integrate conversational signals with existing lead scoring, expansion prediction, and churn prevention models.
Multi-conversation context: Build relationship intelligence by analyzing conversation sequences over time rather than individual interactions.
Compliance and scale: Implement enterprise-grade privacy controls, audit trails, and processing optimization for high-volume conversation analysis.
Conversations as competitive advantage
Every conversation your team has contains intelligence that could drive revenue outcomes. The question is whether you’re systematically capturing and activating that intelligence, or letting it disappear into transcripts that nobody revisits.
Start small. Pick one handoff that frustrates your team and your customers. Build a simple schema. Extract the insights that matter. Then expand from there. The compound value of conversational intelligence grows with every workflow you add.
If you want to see how Clay can help you build conversational intelligence into your GTM workflows, reach out to our team. We’d be happy to show you how we’ve architected these systems and help you think through what would work for your organization.
Another hot tip: use Sculptor to "Chat with table" and you can use AI to analyze data in the table at scale. You can ask all sorts of questions about conversations, or if you have conversations scored, then ask "What is the average score of Discovery calls?" You could do the same thing for each stage and figure out where you should focus enablement efforts.
I see workshops for RevOps teams.